1、大模型预训练中的学习率调整策略都有哪些?
现有的大型语言模型在预训练阶段普遍采用相似的学习率调整策略,这一策略主要包括预热阶段和衰减阶段。预热阶段通常占据整个训练步骤的0.1%至0.5%,随后学习率开始进入衰减阶段。在模型训练的初期,由于参数是随机初始化的,梯度往往较大,因此需要使用较小的学习率来确保训练的稳定性。为了实现这一点,训练中通常采用线性预热策略来平稳地调整学习率。具体来说,学习率会从一个非常小的数值(如0或1×10^-8)开始,线性地增加到预设的最大阈值。当学习率较大时,模型可以更快地收敛,这个最大阈值通常设置在5×10^-5到1×10^-4之间,例如GPT-3的学习率最大值设定为6×10^-5,而LLaMA的学习率最大值则设定为1.5×10^-4。达到最大阈值后,学习率会逐渐衰减,以避免在最优解附近产生震荡。最终,学习率通常会衰减到其最大阈值的10%。常见的衰减策略包括线性衰减、余弦衰减以及平方根倒数衰减,它们的学习率变化如下图所示。
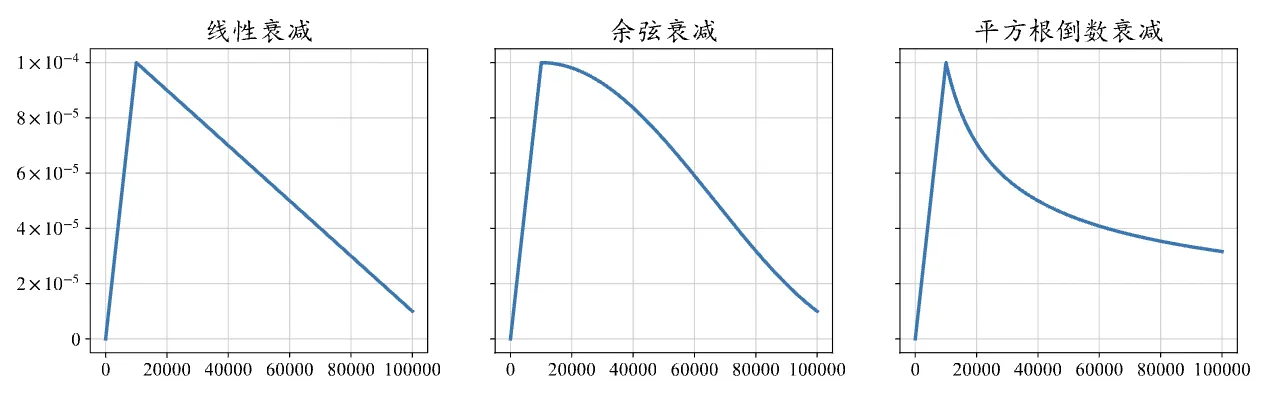
2、请实现一下线性预热和余弦衰减到最大值的 10% 的学习率策略
为了实现线性预热和余弦衰减到最大值的 10% 的学习率策略,可以通过自定义学习率调度器来完成。这里是如何通过 PyTorch 和 DeepSpeed 实现这一策略的步骤。
1. 学习率调度策略
- 线性预热:从 0 开始,学习率逐步增加到设定的最大值(如
lr_max)。 - 余弦衰减:达到最大值后,逐步按照余弦曲线衰减到最大值的 10%。
2. 代码实现
我们通过 LambdaLR 来实现自定义的学习率调度器,该调度器会根据当前的训练步数决定学习率。
import torch
import math
from torch.optim import AdamW
from torch.optim.lr_scheduler import LambdaLR
模型参数和优化器
model = YourModel()
optimizer = AdamW(model.parameters(), lr=1.5e-4) 设置一个较高的最大学习率
设置参数
warmup_steps = 4000 线性预热步数
total_steps = 80000 总训练步数
lr_max = 1.5e-4 最大学习率
lr_min = lr_max * 0.1 最小学习率,即最大值的 10%
自定义学习率调度器:线性预热+余弦衰减
def lr_lambda(current_step):
if current_step < warmup_steps:
线性预热
return float(current_step) / float(max(1, warmup_steps))
余弦衰减
progress = float(current_step - warmup_steps) / float(max(1, total_steps - warmup_steps))
return lr_min / lr_max + 0.5 * (1.0 - lr_min / lr_max) * (1.0 + math.cos(math.pi * progress))
scheduler = LambdaLR(optimizer, lr_lambda=lr_lambda)
测试:打印每一步的学习率变化
for step in range(total_steps):
optimizer.step() 执行优化器的更新
scheduler.step() 更新学习率
if step % 10000 == 0: 每 10000 步打印一次学习率
print(f"Step {step}: Learning Rate = {scheduler.get_last_lr()[0]}")3. 与 DeepSpeed 集成
在 DeepSpeed 中,你可以将自定义的学习率调度器和优化器传递给 deepspeed.initialize,这样在使用 DeepSpeed 分布式训练时依然可以保持这种学习率调整策略。
import deepspeed
DeepSpeed 配置
ds_config = {
"train_batch_size": 32,
"optimizer": {
"type": "AdamW",
"params": {
"lr": 1.5e-4
}
}
}
使用 DeepSpeed 初始化
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
optimizer=optimizer,
lr_scheduler=scheduler, 使用自定义的学习率调度器
config=ds_config
)
在训练循环中进行优化和学习率更新
for step in range(total_steps):
model_engine.step() 执行 DeepSpeed 优化步骤
4. 解释
- 预热阶段:在前
warmup_steps步内,学习率从 0 线性增加到lr_max。 - 余弦衰减阶段:在预热结束后,学习率按余弦曲线衰减,最终下降到
lr_max的 10%,即lr_min。

