1. RLHF的流程
大模型的核心方法非RLHF(reinforcement learning from human feedback)莫属了。简单来说,RLHF是一种让模型从人类反馈中学习的方法。在训练过程中,模型会生成多个可能的输出,然后评估者会对这些输出进行排序。这种排序的信息被用作奖励信号,用于微调模型,使其能对齐人们的偏好。
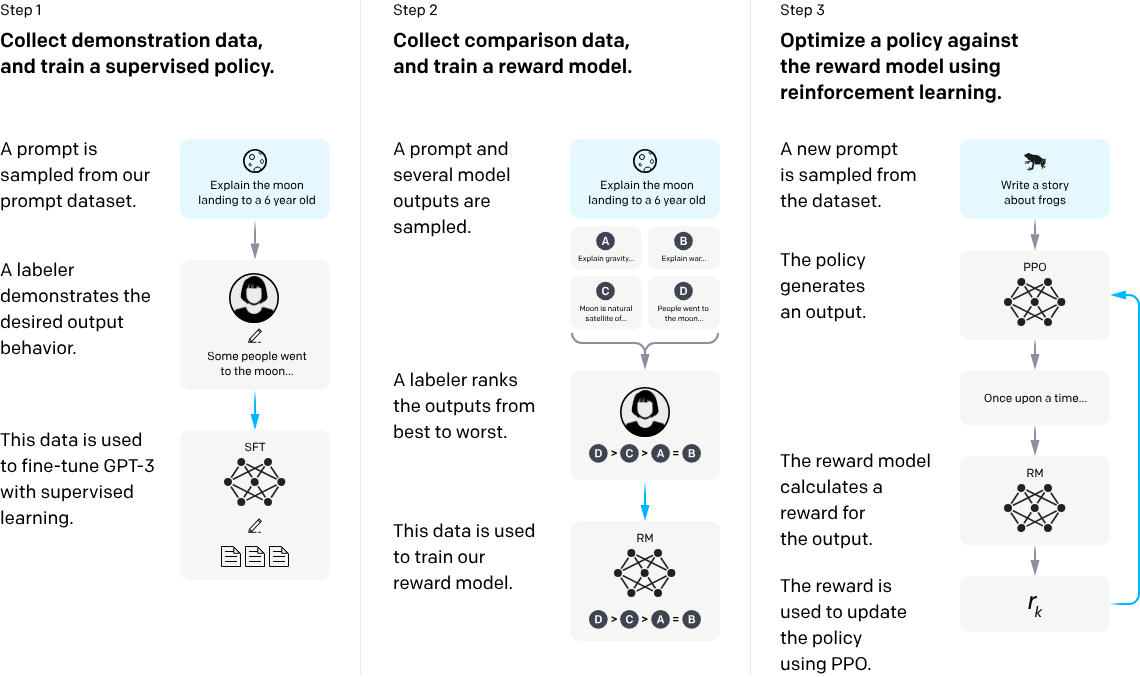
图1是经典的RLHF流程。总共包含3个步骤
- 收集数据,训练一个SFT(Supervised Fine-Tun-ing)模型;
- 收集排序数据,标注者对SFT模型的输出从最好到最坏进行排序,并训练一个具有排序能力的RM(Reward Model);
- 收集输入数据,使用强化学习利用RM使用PPO策略来优化PPO模型(也就是之前的SFT模型,只是模型稍微有些不同);
现在一共涉及到了3个模型,分别是SFT模型,RM模型,PPO模型。下面放了三张图,我们来看一下这3个模型的区别。
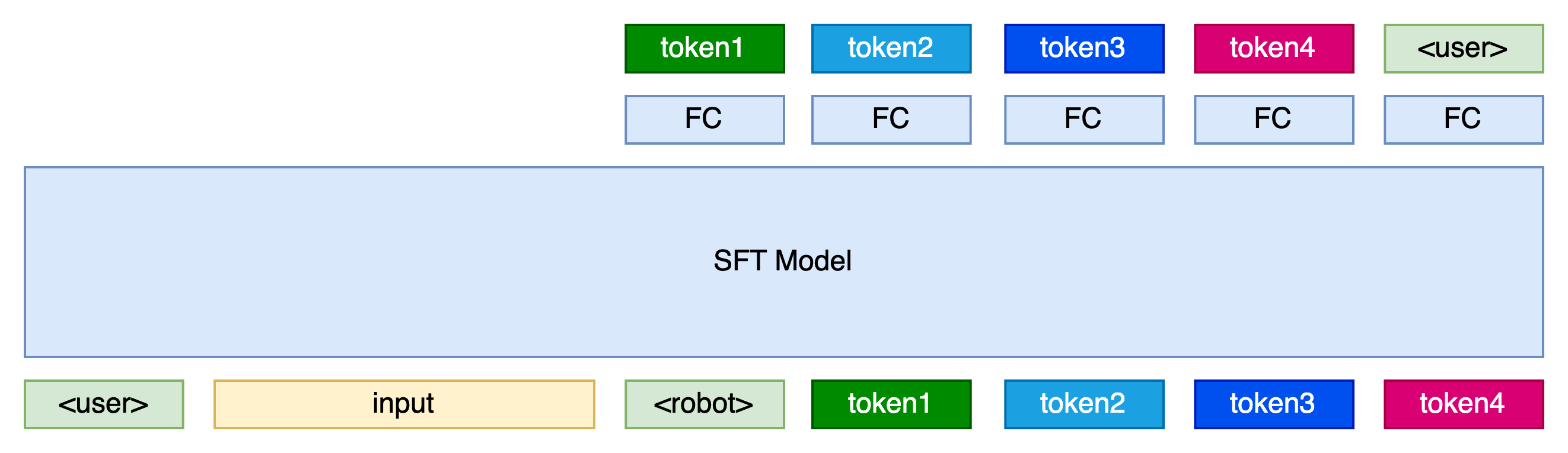

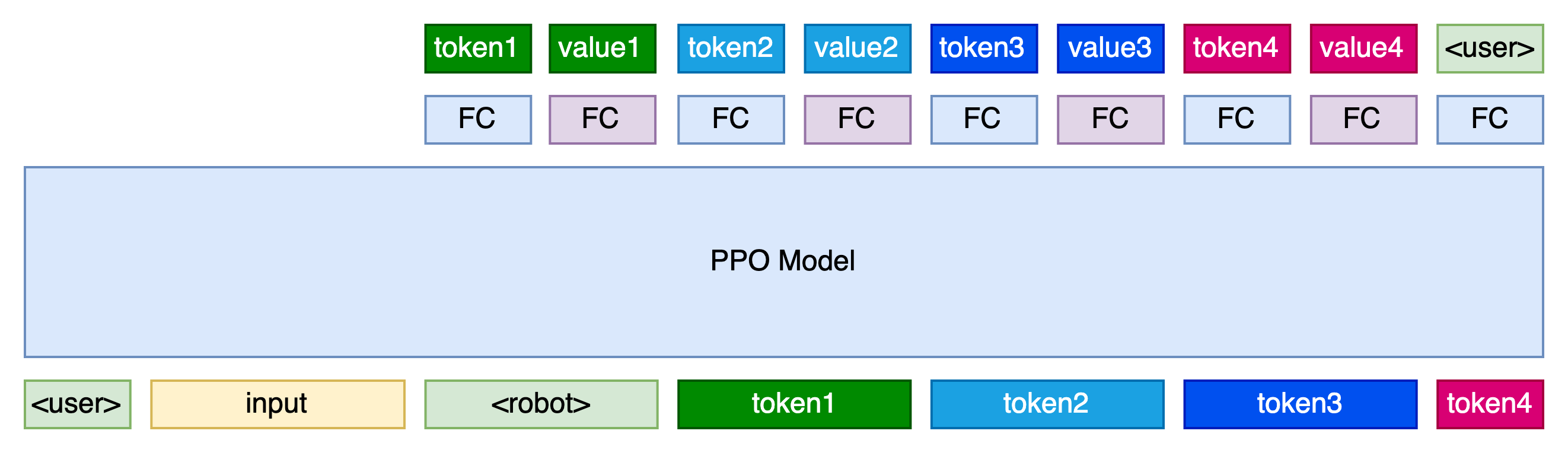
虽然是三个模型,但是它们的基座是相同的,都可以是SFT过后的模型,只是在最后的一层的处理上不同。
RM模型在最后的处进行输出,对整个序列进行打分。PPO模型在SFT模型基础上添加了新的FC层,额外输出了一个value值。PPO模型这样设计的原因是对应一个强化学习概念——策略(policy)。policy由两个模型组成,一个叫做演员模型(Actor),另一个叫做评论家模型(Critic)。它们分别对应图中的两个FC,一个负责决策,一个负责打分。(现在一般拆分成两个单独的模型去训练。)
2. PPO的训练细节
SFT模型和RM模型的训练较为直接,直接用交叉熵损失和排序损失即可。PPO模型的训练较为繁琐,在这里重点讲一下训练PPO的整个算法流程。我们先直接上伪代码
pretrained_model = load_pretrained_model()
sft_model = train(pretrained_model, sft_data)
reward_model = build_reward_model(sft_model.parameter)
reward_model = train(reward_model, rm_data)
ppo_model = build_ppo_model(sft_model.parameter)
def analysis_reward(sft_probs, probs, score):
rewards = log(sft_probs) - log(probs)
rewards[-1] += score
return rewards
def analysis_advantage(rewards, values):
n = len(rewards)
for i in range(n):
total_rewards[i] = sum(rewards[i:n])
advantages = total_rewards - values
return advantages
def analysis_actor_loss(advantages, probs, new_probs):
n = len(advantages)
actor_loss = -(1/n) * sum(advantages * new_probs / probs)
return actor_loss
def analysis_critic_loss(rewards, new_values):
n = len(rewards)
for i in range(n):
total_rewards[i] = sum(rewards[i:n])
critic_loss = 1/(2*N) * sum((new_values - total_rewards)^2)
return critic_loss
// PPO训练过程,所需的data只有query
for _ in range(M):
inputs = sample(query_data)
output_tokens, probs, values = ppo_model(inputs)
score = reward_model(inputs, output_tokens)
// 输出给定output_tokens的概率
sft_probs = sft_model(inputs, output_tokens, predict=Fasle)
rewards = analysis_reward(sft_probs, probs, score)
advantages = analysis_advantage(rewards, values)
// 学习
for epoch in range(N):
// 输出给定output_tokens的概率和价值
new_probs, new_values = ppo_model(inputs, output_tokens, predict=Fasle)
actor_loss = analysis_actor_loss(advantages, probs, new_probs)
critic_loss = analysis_critic_loss(rewards, new_values)
loss = actor_loss + ALPHA * critic_loss
train(ppo_model, loss)
挑几个重点讲一下。
analysis_reward函数是分析ppo模型输出的最终奖励函数,这个最终奖励分为两个部分,分别是过程合理性奖励和结果正确性奖励。log(sft_probs) - log(probs)是ppo模型预测的概率和sft模型预测的概率的差值,可以认为是过程合理性奖励。第一项log(sft_probs) 可以认为是sft模型对ppo模型的“认可度”,第二项-log(probs)可以认为是ppo模型的正则项,要求尽可能生成多样性的内容。最后一个token的reward加上rm预测的分数可以认为是结果正确性奖励。
analysis_advantage函数是分析当前奖励领先值函数(vlaue,Critic的输出)的领先程度。每一步的advantage是当前奖励累计到最后一个token的总奖励减去当前的value值。
analysis_actor_loss函数是计算“演员”的损失,由以下公式(简化版)得出,advantage相当于权重,不参与梯度回传。
\text{actor\_loss} = -\frac{1}{N}\sum\limits_{i=1}^N \text{advantage}[i] \times \frac{p_{new}(\text{token[i]})}{p(\text{token[i]})}analysis_critic_loss函数是计算“评论家”的损失,由以下公式(简化版)得出
\text{critic\_loss} = \frac{1}{2N}\sum\limits_{i=1}^N(\text{values}[i] - \text{total\_rewards}[i])^2上述公式做了简化,没有考虑广义优势估计(GAE)、PPO-Clip。可以阅读相关资料来了解细节:TRPO 算法、PPO算法
至此整个训练PPO的整个算法流程介绍完了,欢迎大家学习交流、关注分享~

